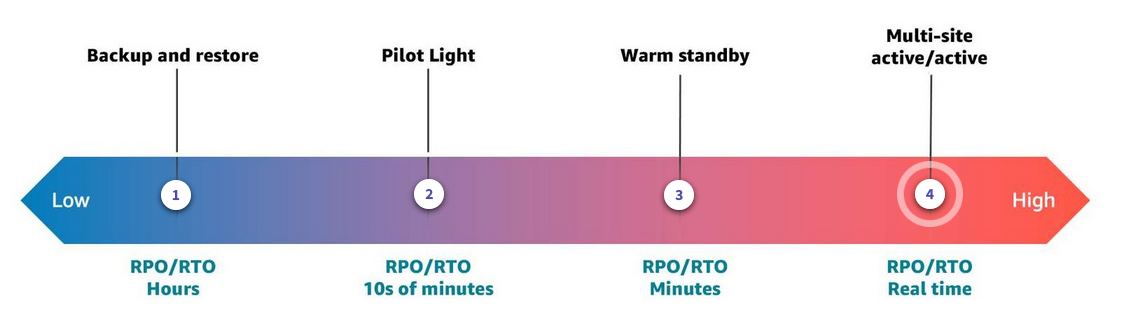
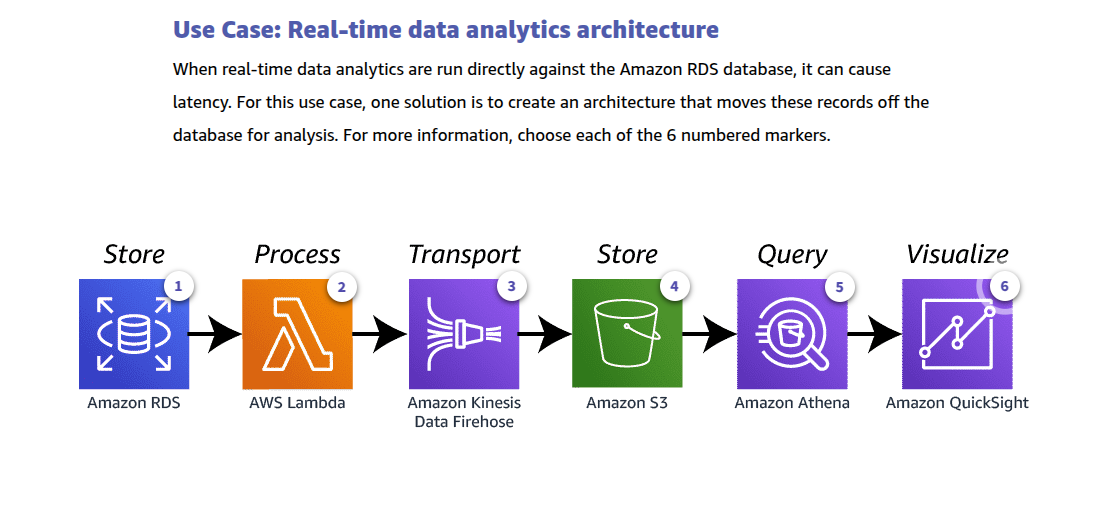
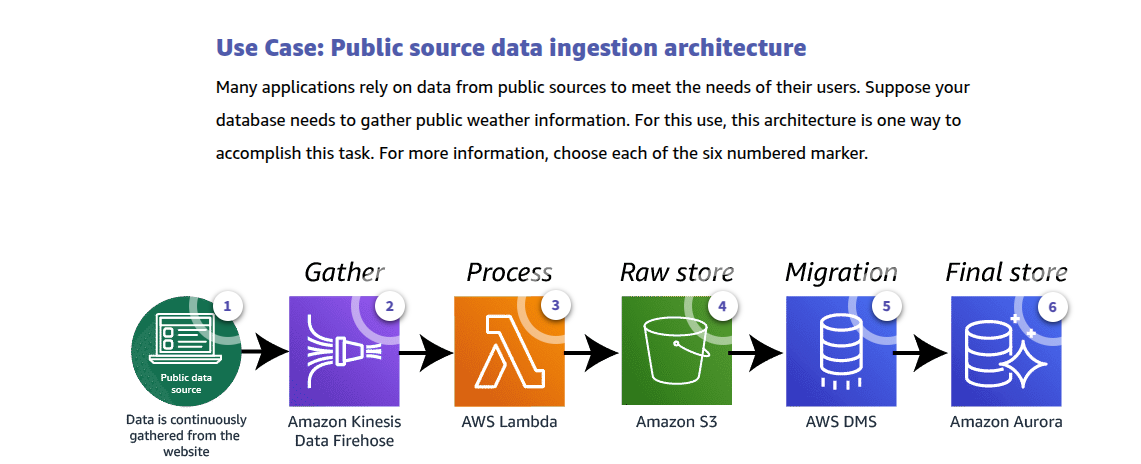
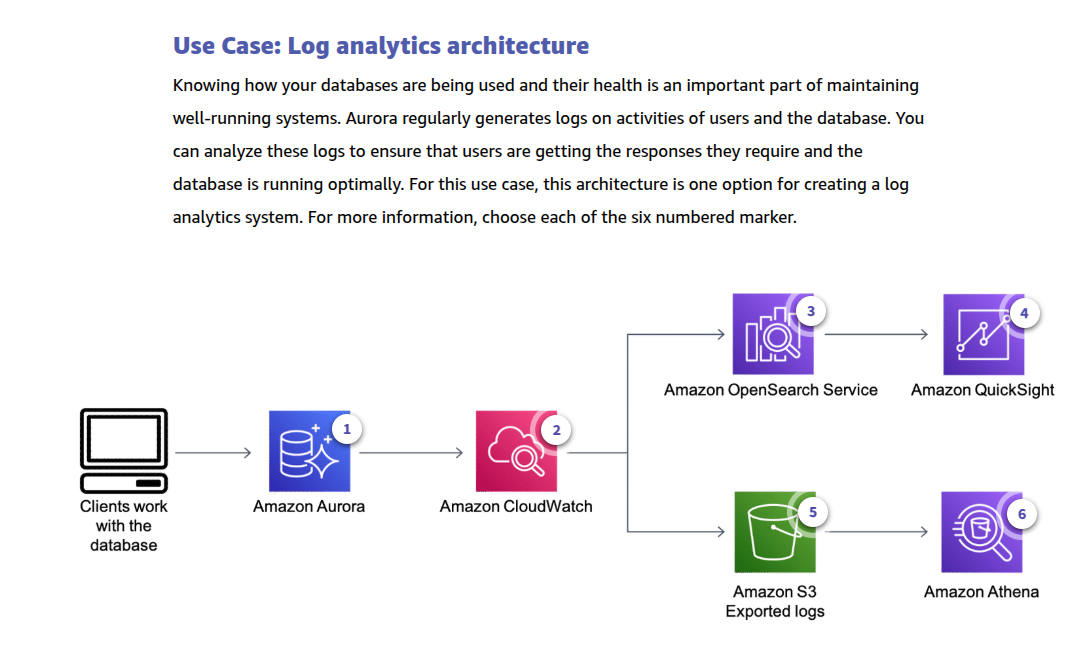
Nonrelational database types
To learn more, expand each of the following seven categories.
Key-value databases–
Key-value databases logically store data in a single table. Within the table, the values are associated with a specific key and stored in the form of blob objects without a predefined schema. The values can be of nearly any type.
Strengths
- They are very flexible.
- They can handle a wide variety of data types.
- Keys are linked directly to their values with no need for indexing or complex join operations.
- Content of a key can easily be copied to other systems without reprogramming the data.
Weaknesses
- Analytical queries are difficult to perform due to the lack of joins.
- Access patterns need to be known in advance for optimum performance.
AWS service
- Amazon DynamoDB
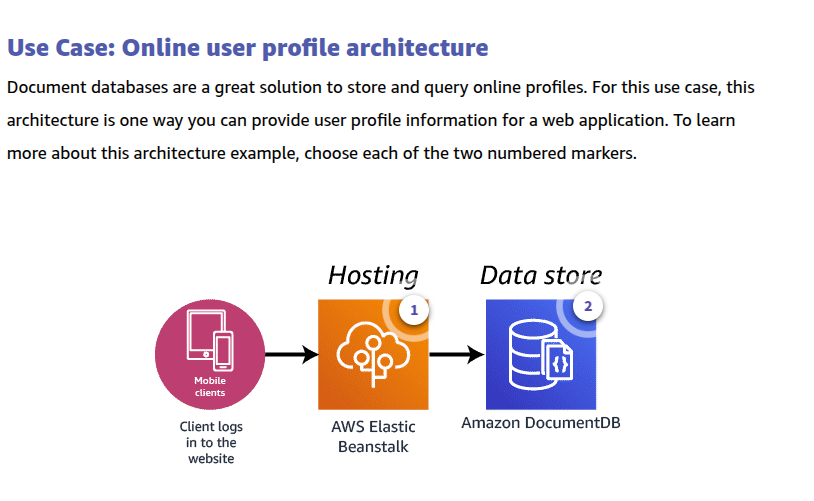
Document databases–
Document stores keep files containing data as a series of elements. These files can be navigated using numerous languages including Python and Node.js. Each element is an instance of a person, place, thing, or event. For example, a document store may hold a series of log files from a set of servers. These log files can each contain the specifics for that system without concern for what the log files in other systems contain.
Strengths
- They are flexible.
- There is no need to plan for a specific type of data when creating one.
- They are scalable.
Weaknesses
- You sacrifice ACID compliance for flexibility.
- Databases cannot query across files natively.
AWS service
- Amazon DocumentDB (with MongoDB compatibility)
In-memory databases–
In-memory databases are used for applications that require real-time access to data. Most databases have areas of data that are frequently accessed but seldom updated. Additionally, querying a database is always slower and more expensive than locating a key in a key-value pair cache. Some database queries are especially expensive to perform. By caching such query results, you pay the price of the query once and then are able to quickly retrieve the data multiple times without having to rerun the query.
Strengths
- They support the most demanding applications requiring sub-millisecond response times.
- They are great for caching, gaming, and session store.
- They adapt to changes in demands by scaling out and in without downtime.
- They provide ultrafast (sub-microsecond latency) and inexpensive access to copies of data.
Weaknesses
- They are not suitable for data that is rapidly changing or is seldom accessed.
- Application using the in-memory store has a low tolerance for stale data.
AWS service
- Amazon ElastiCache
- Amazon MemoryDB for Redis
Graph databases–
Graph databases store data as nodes, while edges store information on the relationships between nodes. Data within a graph database is queried using specific languages associated with the software tool you have implemented.
Strengths
- They allow straightforward, fast retrieval of complex hierarchical structures.
- They are great for real-time big data mining.
- They can rapidly identify common data points between nodes.
- They are great for making relevant recommendations and allowing for rapid querying of those relationships.
Weaknesses
- They cannot adequately store transactional data.
- Analysts must learn new languages to query the data.
- Performing analytics on the data may not be as efficient as with other database types.
AWS service
- Amazon Neptune
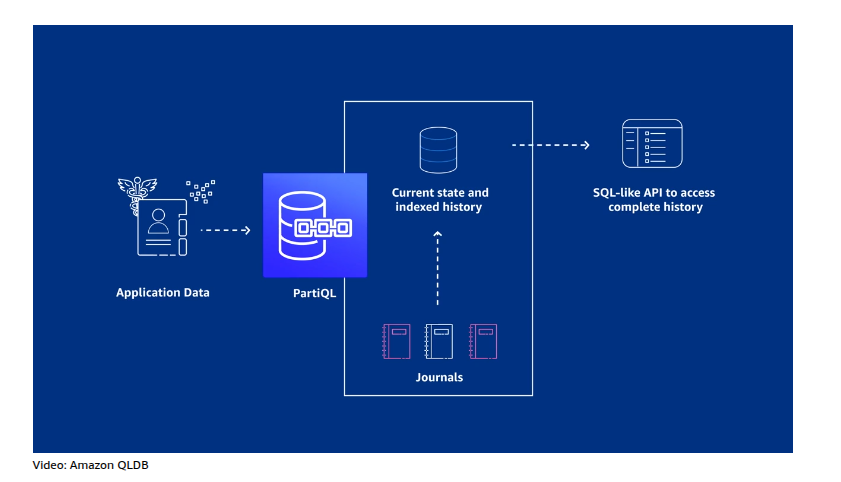
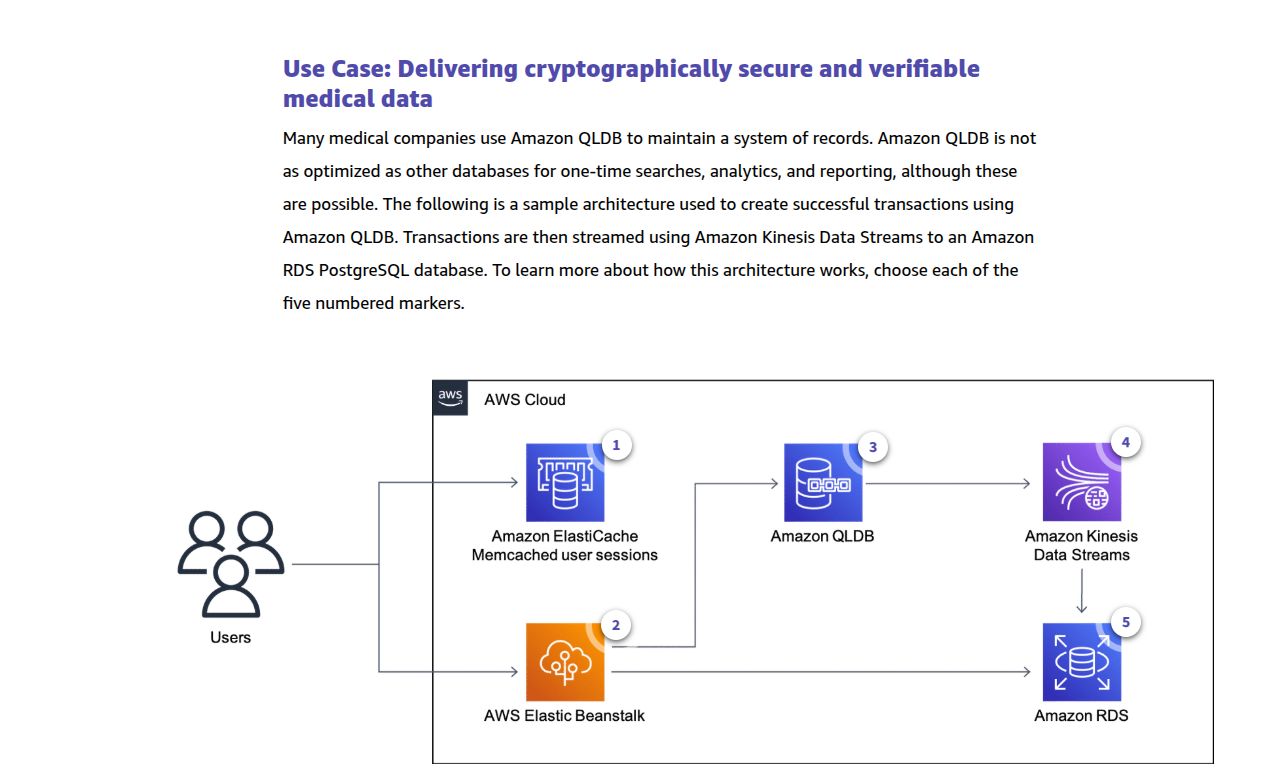
Ledger databases–
Ledger databases are used for operations in which your data is immutable. That is, it cannot be changed. This is useful for banking records, cryptocurrency, and more. Once data is written to a ledger database, it cannot be modified. Where in standard databases, you could update a customer’s address, in a ledger database, this would become an entirely new record. The old record and address would remain. For banking, legal, crypto, and others this is extremely useful as there is a record over time. You would actually be able to see the changes your customers have made over time as an example.
Strengths
- Records are immutable.
- You can track changes over time.
- You can legally prove that data has not been altered.
Weaknesses
- Data cannot be changed if inputted incorrectly.
AWS service
- Amazon Quantum Ledger Database (Amazon QLDB)
Time series databases–
Often in databases, you are interested in simply a moment in time, or a relation to two or more items. Time-series databases, however, focus on data changing over time. Imagine if you want to see how popular a hashtag was. Knowing how many times it was used might be useful, but what might be more useful is looking at how the usage changed by the hour or by the day. This type of data is what time-series databases specialize in. They can also be used to monitor server or central processing unit (CPU) loads over time. The key to remember is that, as implied by the name, time is always going to play a part in these databases.
Strengths
- You can see how certain metrics change over the course of specific time intervals.
Weaknesses
- They are appropriate for very specific uses involved in time and not flexible for other needs.
AWS service
- Amazon Timestream
Wide-column databases–
Wide-column databases are NoSQL databases that organize data storage into columns and rows that can then be placed into column families. The data in each family can be different and have a different number of columns and rows.
Strengths
- They support a large volume of data.
- They are scalable.
- They have fast write speeds.
Weaknesses
- It is not easy to work with changing database requirements.
AWS service
- Amazon Keyspaces (for Apache Cassandra)
Key Differences
| Feature | Redshift Spectrum | Amazon Athena |
|---|---|---|
| Integration | Integrates with Redshift data warehouse. Can join Redshift and S3 data in a single query. | Completely serverless; standalone service for querying S3 data. |
| Performance | Optimized for large-scale, complex queries with MPP (Massively Parallel Processing). | Performance varies based on query complexity, but doesn’t match the power of Redshift. |
| Data Loading | Works with data already loaded into Redshift and data in S3. | No need to load data, just query directly from S3. |
| Infrastructure | Requires a Redshift cluster. | Serverless — no infrastructure management required. |
| Pricing | Pays for compute (Redshift cluster) and data scanned from S3. | Pays only for data scanned by Athena (no compute charges). |
| Data Types Supported | Works with structured and semi-structured data. | Works well with structured and semi-structured data, particularly optimized for columnar formats (e.g., Parquet, ORC). |
| Use Case | Best for large-scale data warehousing with hybrid S3 and Redshift workloads. | Best for ad-hoc queries and exploratory analysis of S3 data. |
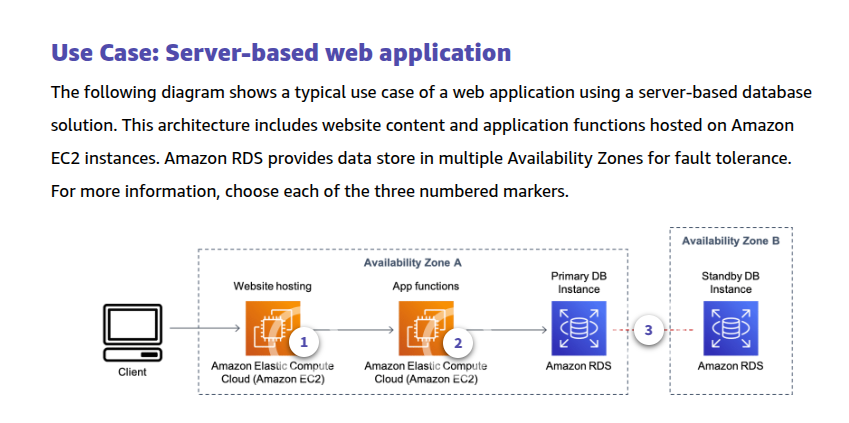
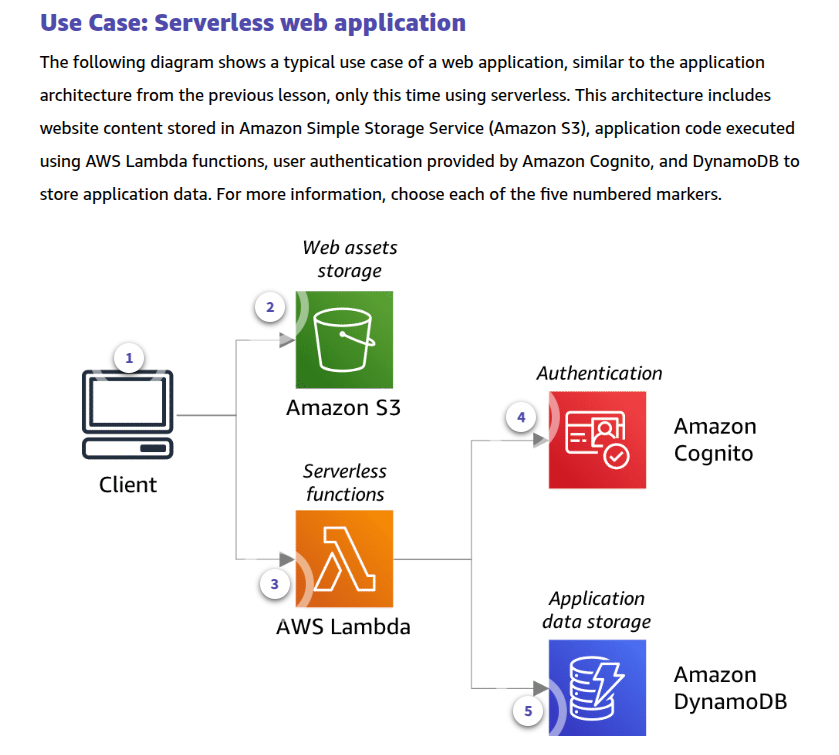
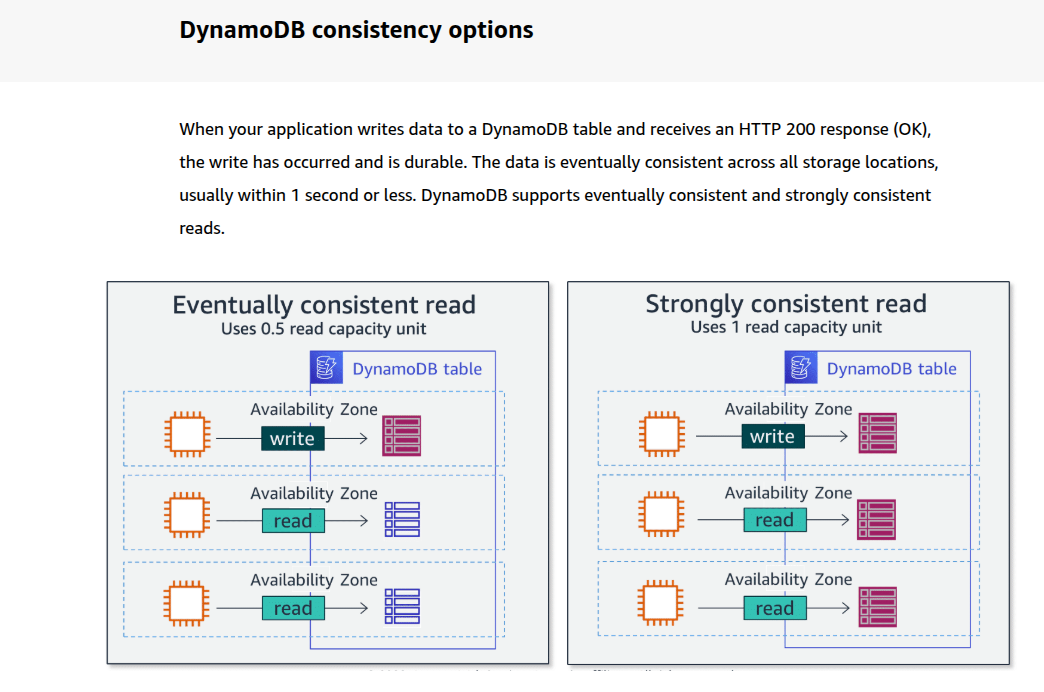
To learn more about read operations, expand each of the following two categories.
Eventually consistent reads
When you read data from a DynamoDB table, the response might not reflect the results of a recently completed write operation. The response might include some stale data. If you repeat your read request after a short time, the response should return the latest data.
Strongly consistent reads
When you request a strongly consistent read, DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful. A strongly consistent read might not be available if there is a network delay or outage.
DynamoDB uses eventually consistent reads, unless you specify otherwise. Read operations (such as GetItem, Query, and Scan) provide a ConsistentRead parameter. If you set this parameter to true, DynamoDB uses strongly consistent reads during the operation.

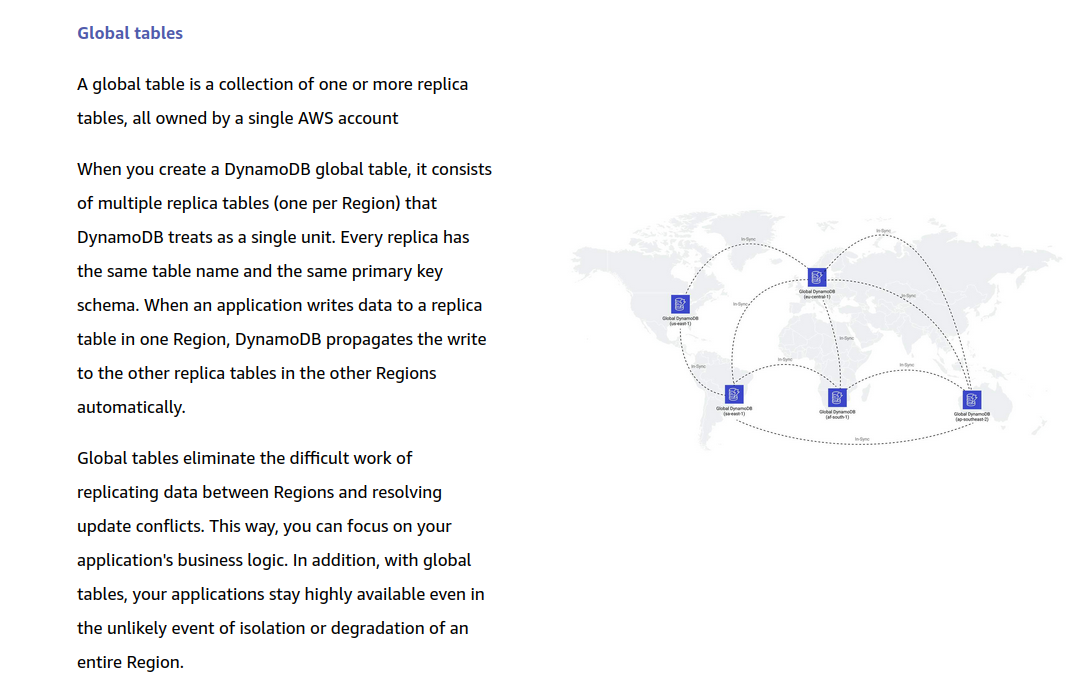
Global Tables and Consistency
When you’re using DynamoDB Global Tables, all cross-region replication is eventually consistent. Here’s what that means:
Within a Single Region:
- You can use strongly consistent reads.
- These reads will reflect the latest write within that region only.
Across Regions:
- Strongly consistent reads are not supported across regions.
- All cross-region reads are eventually consistent, due to asynchronous replication.
| Scenario | Strongly Consistent Read Possible? | Notes |
|---|---|---|
| Same region as the write | Yes | Uses 2 RCUs per strongly consistent read |
| Different region than write | No | Cross-region reads are eventually consistent |
What is an RCU?
RCU (Read Capacity Unit) is how DynamoDB measures the cost of reading data when you’re using provisioned capacity mode.
How RCUs Are Calculated
Each RCU allows you to perform:
- 1 strongly consistent read per second of an item up to 4 KB in size
- 2 eventually consistent reads per second of an item up to 4 KB in size
- 1 transactional read per second of an item up to 4 KB (uses 2 RCUs per read)
If your item is larger than 4 KB, the number of RCUs required scales linearly.
Examples
1. Reading 4 KB item:
- Eventually consistent: 0.5 RCU
- Strongly consistent: 1 RCU
- Transactional read: 2 RCUs
2. Reading 12 KB item:
- Eventually consistent: (12 / 4) × 0.5 = 1.5 RCUs
- Strongly consistent: (12 / 4) × 1 = 3 RCUs
- Transactional read: (12 / 4) × 2 = 6 RCUs
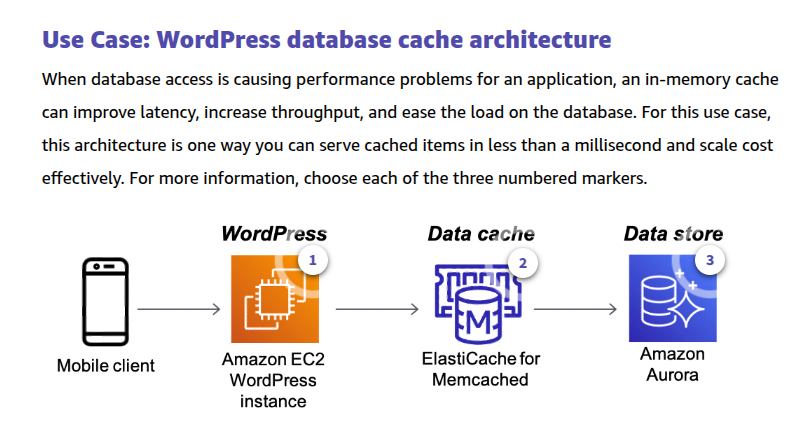
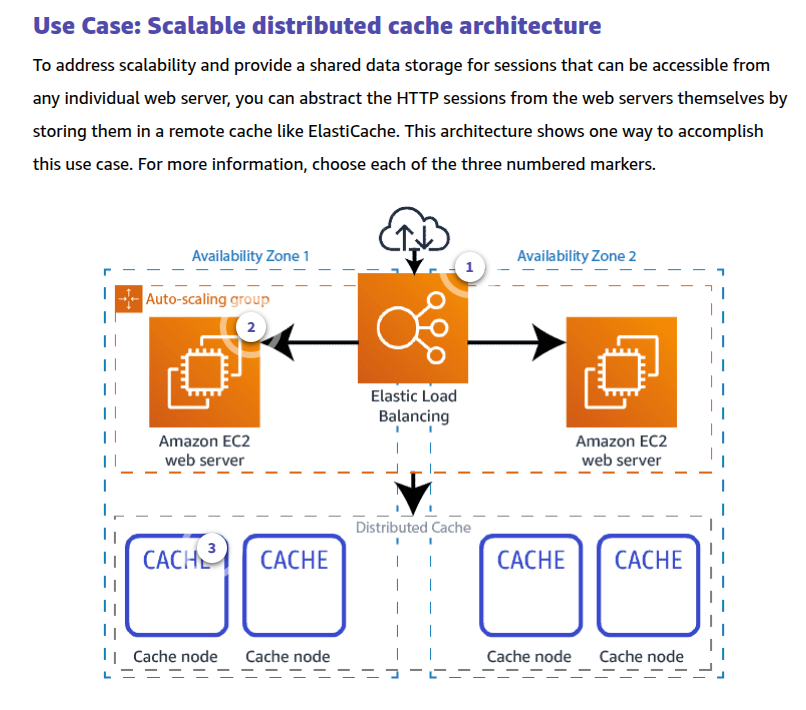
Amazon ElastiCache

Amazon ElastiCache is a web service that makes it easy to set up, manage, and scale a distributed in-memory data store or cache environment in the cloud. It provides a high-performance, scalable, and cost-effective caching solution. At the same time, it helps remove the complexity associated with deploying and managing a distributed cache environment.
ElastiCache works with two open-source compatible in-memory data stores – Redis, Memcached engines.
ElastiCache for Redis is an in-memory data store that provides sub-millisecond latency at internet scale. ElastiCache for Redis combines the speed, simplicity, and versatility of open-source Redis with manageability, security, and scalability from Amazon. It can power the most demanding real-time applications in gaming, ad tech, ecommerce, healthcare, financial services, and Internet of Things (IoT).
With ElastiCache for Memcached, you can build a scalable caching tier for data-intensive apps. The service works as an in-memory data store and cache to support the most demanding applications requiring sub-millisecond response times. ElastiCache for Memcached is fully managed, scalable, and secure, making it a good candidate for use cases where frequently accessed data must be in memory. This engine offers a simple caching model with multi-threading. The service is a popular choice for use cases such as web, mobile apps, gaming, ad tech, and ecommerce. The Memcached-compatible service also supports Auto Discovery.
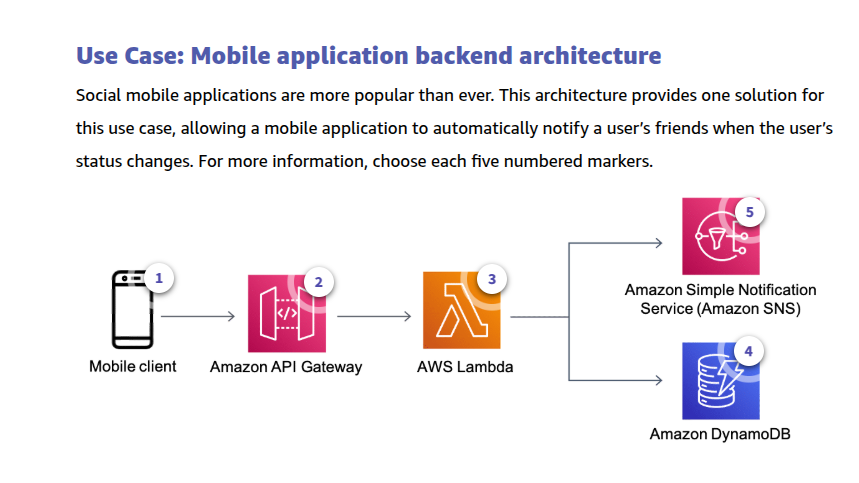
DynamoDB Accelerator (DAX)
DynamoDB is designed for scale and performance. In most cases, the DynamoDB response times can be measured in single-digit milliseconds. However, there are certain use cases that require response times in microseconds. For those use cases, DynamoDB Accelerator (DAX) delivers fast response times for accessing eventually consistent data.

DAX is a caching service compatible with DynamoDB that provides fast in-memory performance for demanding applications.
You create a DAX cluster in your Amazon VPC to store cached data closer to your application. You install a DAX client on the Amazon EC2 instance running your application in that VPC. At runtime, the DAX client directs all of your application’s DynamoDB requests to the DAX cluster. If DAX can process a request directly, it does so. Otherwise, it passes the request through to DynamoDB.
CloudWatch alarms
A CloudWatch alarm can be created based on a single cloud metric known as a metric alarm or on a composition of multiple cloud metrics known as a composite alarm. The alarm performs one or more actions based on the value of the metric or expression relative to a threshold over a number of time periods.
Alarm states
An alarm has three possible states. To learn more about each type of alarm, expand each of the three alarm states.
OK
The metric is within the defined threshold.
ALARM
ALARM is only a name given to the state and does not necessarily signal an emergency condition requiring immediate attention. It means that the monitored metric is equal to, greater than, or less than a specified threshold value. You could, for example, define an alarm that tells you when your CPU utilization for a given EC2 instance is too high. You might process this notification programmatically to suspend a CPU-intensive job on the instance. You can also send a notification to take action to notify the application owner.
INSUFFICIENT_DATA
INSUFFICIENT_DATA can be returned when no data exists for a given metric. An example of this is the depth of an empty Amazon Simple Queue Service (Amazon SQS) queue. This can also be an indicator that something is wrong in your system.
Amazon EventBridge
Amazon EventBridge is a serverless event bus that makes it easier to build event driven applications at scale using events generated from your applications, integrated software-as-a-service (SaaS) applications and AWS services. EventBridge receives an event (an indicator of a change in environment), and applies a rule to route the event to a target. EventBridge is the preferred way to manage your events captured in CloudWatch.
In the example, an EC2 instance reports the CPUUtilization metric data to CloudWatch. A custom alarm is created and configured, called “CPUAbove90Percent,” so that you will know when the EC2 instance is being overused.
EventBridge rules are built to notify your support team when the CPUAbove90Percent alarm is in ALARM state, so that they can investigate and take action. EventBridge takes two actions: it sends an email to subscribed recipients using the Amazon Simple Notification Service (Amazon SNS) topic, and sends a rich notification to the operation team’s third-party monitoring tool.
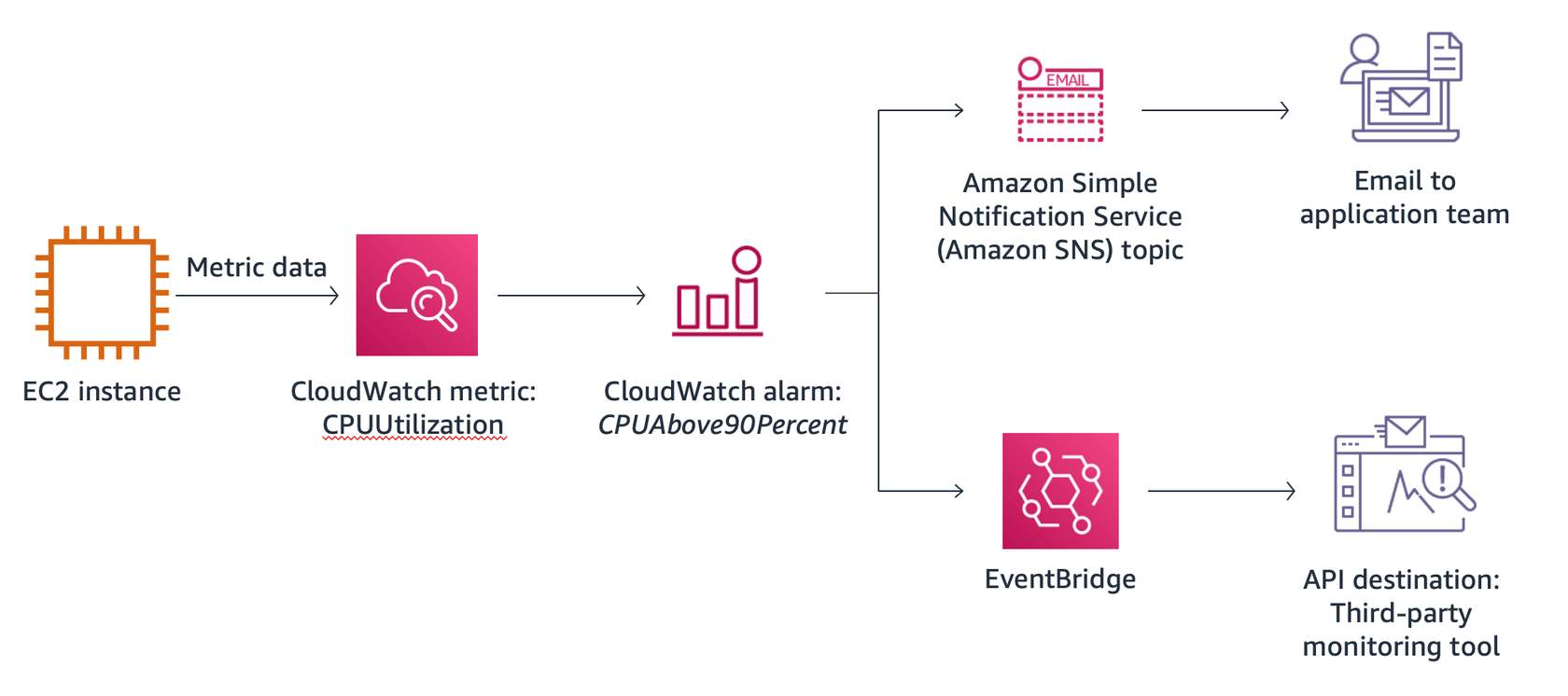
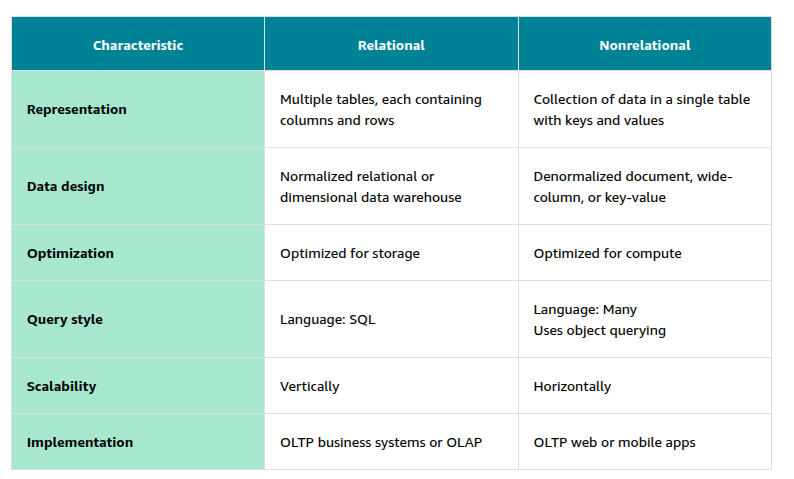
Amazon API Gateway is an AWS service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs at any scale.
With API Gateway, you can connect your applications to AWS services and other public or private websites. It provides consistent RESTful and HTTP APIs for mobile and web applications to access AWS services and other resources hosted outside of AWS.
As a gateway, it handles all of the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls. These include traffic management, authorization and access control, monitoring, and API version management.

With Amazon Kinesis, you can do the following:
- Collect, process, and analyze data streams in real time. Kinesis has the capacity to process streaming data at virtually any scale. It provides you with the flexibility to choose the tools that best suit the requirements of your application in a cost-effective way.
- Ingest real-time data such as video, audio, application logs, website clickstreams, and Internet of Things (IoT) telemetry data. The ingested data can be used for machine learning, analytics, and other applications.
- Process and analyze data as it arrives and respond instantly. You don’t need to wait until all the data is collected before the processing begins.
To learn more, choose each hotspot.

Kinesis Data Streams overview
To get started using Kinesis Data Streams, create a stream and specify the number of shards. Each shard is a uniquely identified sequence of data records in a stream. Your stream can receive 1 MB per second per shard. Each shard has a read limit of 2 MB per second for your applications. The total capacity of a stream is the sum of the capacities of its shards. Use resharding to increase or decrease the number of shards in your stream as needed.
To learn more, choose each of the numbered markers.

Kinesis Data Firehose overview
Amazon Kinesis Data Firehose offers a way to capture, transform, and load data streams into AWS data stores for near-real-time analytics with existing business intelligence tools.
To learn more, choose each of the numbered markers.

With Step Functions, you can create two types of workflows: Standard and Express. To learn more about each type of workflow, expand each of the following two categories.
Standard workflows
Use the Standard workflows type for long-running, durable, and auditable workflows. These workflows can run for up to a year, and you can access the full history of workflow activity for up to 90 days after a workflow completes. Standard workflows use an exactly-once model, where your tasks and states are never run more than once unless you specify a Retry behavior.
Express workflows
Use the Express workflows type for high-volume, event-processing workloads such as IoT data ingestion, streaming data processing and transformation, and mobile application backends. They can run for up to 5 minutes. Express workflows use an at-least-once model, where there is a possibility that an execution might be run more than once.

Routing policies
When you create a record, you choose a routing policy, which determines how Amazon Route 53 responds to queries.
To learn more, expand each of the following seven categories.
Simple routing policy
Use for a single resource that performs a given function for your domain—for example, a web server that serves content for the example.com website. You can use simple routing to create records in a private hosted zone.

Failover routing policy
Use when you want to configure active-passive failover. You can use failover routing to create records in a private hosted zone.

Geolocation routing policy
Use when you want to route traffic based on the location of your users. You can use geolocation routing to create records in a private hosted zone.

Geoproximity routing policy
Use when you want to route traffic based on the location of your resources and, optionally, shift traffic from resources in one location to resources in another.

Latency routing policy
Use when you have resources in multiple AWS Regions and you want to route traffic to the Region that provides the best latency. You can use latency routing to create records in a private hosted zone.

Multivalue answering routing policy
Use when you want Route 53 to respond to DNS queries with up to eight healthy records selected at random. You can use multivalue answer routing to create records in a private hosted zone.

Weighted routing policy
Use to route traffic to multiple resources in proportions that you specify. You can use weighted routing to create records in a private hosted zone.

In this lesson, you learned how to use Amazon Route 53 in your appli
DDoS attacks
A DDoS attack is an attack in which multiple compromised systems attempt to flood a target, such as a network or web application, with traffic. A DDoS attack can prevent legitimate users from accessing a service, and can cause the system to crash due to the overwhelming traffic volume.

The general concept of a DDoS attack is to use additional hosts to amplify the requests made to the target, rendering them at full capacity and unavailable.
OSI layer attacks
In general, DDoS attacks can be isolated by the Open Systems Interconnection (OSI) model layer they attack. They are most common at the Network (Layer 3), Transport (Layer 4), Presentation (Layer 6), and Application (Layer 7) layers.

to learn more, expand each of the two categories.
Infrastructure layer attacks
Attacks at Layers 3 and 4 are typically categorized as infrastructure layer attacks. These are also the most common type of DDoS attack and include vectors like synchronized (SYN) floods and other reflection attacks like User Datagram Protocol (UDP) packet floods. These attacks are usually large in volume and aim to overload the capacity of the network or the application servers. But fortunately, these are also the type of attacks that have clear signatures and are easier to detect.
Application layer attacks
An attacker might target the application itself by using a Layer 7, or Application layer, attack. In these attacks, similar to SYN flood infrastructure attacks, the attacker attempts to overload specific functions of an application to make the application unavailable or extremely unresponsive to legitimate users.
AWS Shield
AWS Shield is a managed DDoS protection service that safeguards your applications that run on AWS. It provides you with dynamic detection and automatic inline mitigations that minimize application downtime and latency.
AWS Shield provides you with protection against some of the most common and frequently occurring infrastructure (Layer 3 and 4) attacks. This includes SYN/UDP floods and reflection attacks. It improves availability of your applications on AWS. The service applies a combination of traffic signatures, anomaly algorithms, and other analysis techniques. AWS Shield detects malicious traffic, and it provides real-time issue mitigation.
AWS WAF
AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits and bots. With AWS WAF, you have control over how traffic reaches your applications. Create security rules that control bot traffic and block common attack patterns, such as SQL injection (SQLi) or cross-site scripting (XSS). You can also monitor HTTP(S) requests that are forwarded to your compatible AWS services.

Before you configure AWS WAF, you should understand the components used to control access to your AWS resources.
- Web ACLs – You use a web ACL to protect a set of AWS resources. You create a web ACL, and define its protection strategy by adding rules.
- Rules – Rules define criteria for inspecting web requests and specify how to handle requests that match the criteria.
- Rule groups – You can use rules individually, or in reusable rule groups. AWS Managed Rules for AWS WAF and AWS Marketplace sellers provide managed rule groups for your use. You can also define your own rule groups.
- Rule statements – This is the part of a rule that tells AWS WAF how to inspect a web request. When AWS WAF finds the inspection criteria in a web request, it means that the web request matches the statement.
- IP set – This is a collection of IP addresses and IP address ranges that you want to use together in a rule statement. IP sets are AWS resources.
- Regex pattern set – This is a collection of regular expressions that you want to use together in a rule statement. Regex pattern sets are AWS resources.
- Monitoring and logging – You can monitor web requests, web ACLs, and rules by using CloudWatch. You can also activate logging to get detailed information about traffic that is analyzed by your web ACL. You choose where to send your logs: CloudWatch Logs, Amazon S3, or Amazon Kinesis Data Firehose.
Control traffic with ACL rule statements
Rule statements are the part of a rule that tells AWS WAF how to inspect a web request. Every rule statement has these attributes:
- It specifies what to look for, and how, according to the statement type.
- It has a single, top-level rule statement that can contain other statements.

AWS Firewall Manager

AWS Firewall Manager simplifies the administration and maintenance tasks of your AWS WAF and Amazon VPC security groups. Set up your AWS WAF firewall rules, AWS Shield protections, and Amazon VPC security groups at one time. The service automatically applies the rules and protections across your accounts and resources, even as you add new resources. Firewall Manager helps you do the following tasks:
- Simplify rule management across applications and accounts
- Automatically discover new accounts and remediate noncompliant events
- Deploy AWS WAF rules from the AWS Marketplace
- Activate rapid response to attacks across all accounts
As new applications are created, Firewall Manager also facilitates bringing new applications and resources into compliance with a common set of security rules from day one. Now you have a single service to build firewall rules, create security policies, and enforce them in a consistent, hierarchical manner across your entire AWS infrastructure.