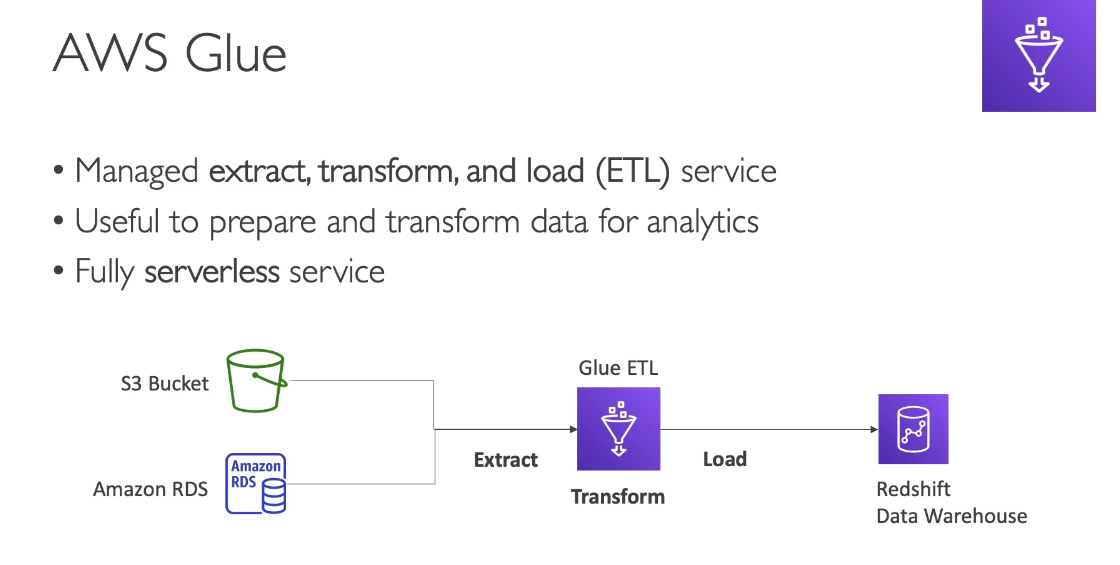
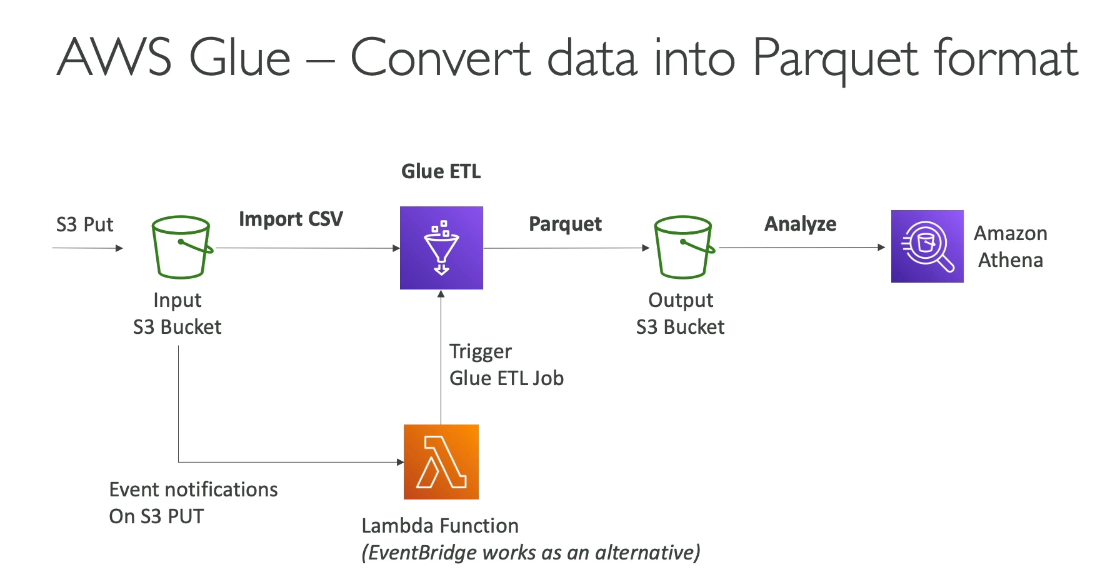
AWS Glue is a fully managed ETL (Extract, Transform, and Load) service provided by Amazon Web Services. It is designed to prepare and transform data for analytics and machine learning workflows by automating the processes of data discovery, cataloging, and preparation.
Key Features of AWS Glue
ETL (Extract, Transform, Load):
Build, manage, and run ETL workflows to transform data from source to target.
Supports structured, semi-structured, and unstructured data.
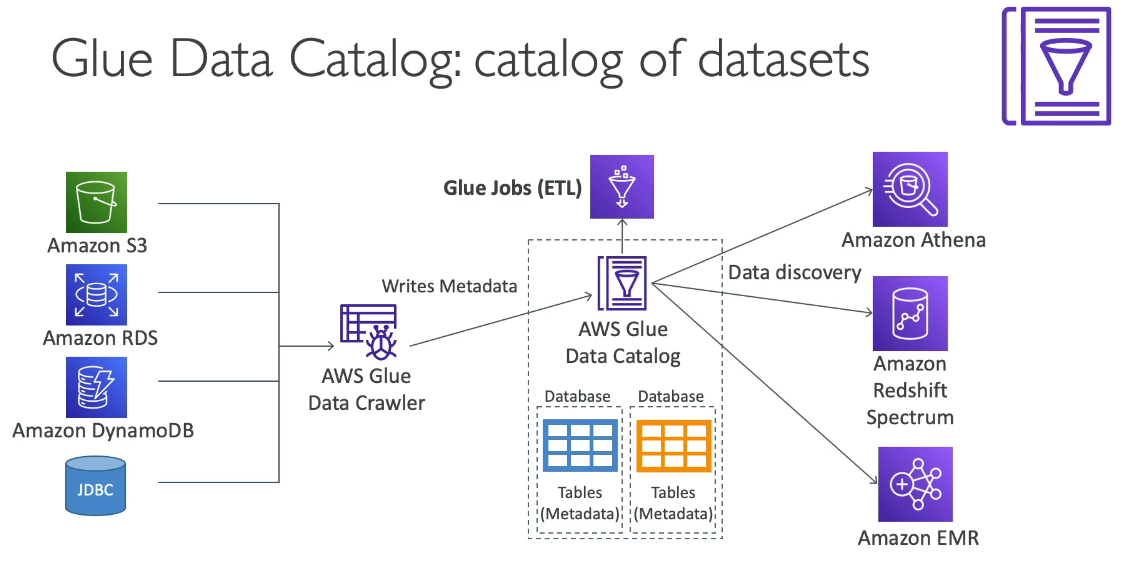
AWS Glue Data Catalog:
A centralized metadata repository for discovering and managing datasets.
Automatically populates metadata (e.g., schema, data format) by crawling data sources like Amazon S3, RDS, DynamoDB, and Redshift.
Provides integration with other AWS services like Athena, Redshift, and EMR.
Glue Studio:
A visual interface to design, run, and monitor ETL jobs.
Drag-and-drop UI for building ETL workflows without requiring deep programming knowledge.
Glue DataBrew:
A no-code/low-code visual data preparation tool for cleaning and enriching data.
Perform transformations like filtering, deduplication, and standardization.
Serverless:
No infrastructure management. Automatically provisions resources to handle ETL workloads.
Pay-as-you-go pricing based on the resources used.
Broad Integration:
Integrates seamlessly with S3, Redshift, DynamoDB, RDS, Kafka, and other AWS services.
Supports third-party tools and APIs.
Support for Multiple Languages:
Code your ETL jobs using Python (PySpark) or Scala with Apache Spark.
Offers Glue-specific libraries to simplify ETL scripting.
Streaming ETL:
Process real-time data streams from Amazon Kinesis or Kafka.
Enable near-real-time data transformations and loading.
Glue Schema Registry:
Manage and validate schemas for streaming data in applications.
Supports formats like Apache Avro, JSON Schema, and Protobuf.
AWS Glue Components
Jobs:
Represents the ETL script that performs data extraction, transformation, and loading.
Can be scheduled or triggered by events (e.g., new file upload in S3).
Crawlers:
Automatically scan data sources to infer schema and populate the Glue Data Catalog.
Triggers:
Set up to automatically start jobs based on schedules or events.
Endpoints:
For interactive development and testing of ETL jobs using development notebooks.
Dev Endpoints:
Allow developers to create and debug ETL scripts interactively.