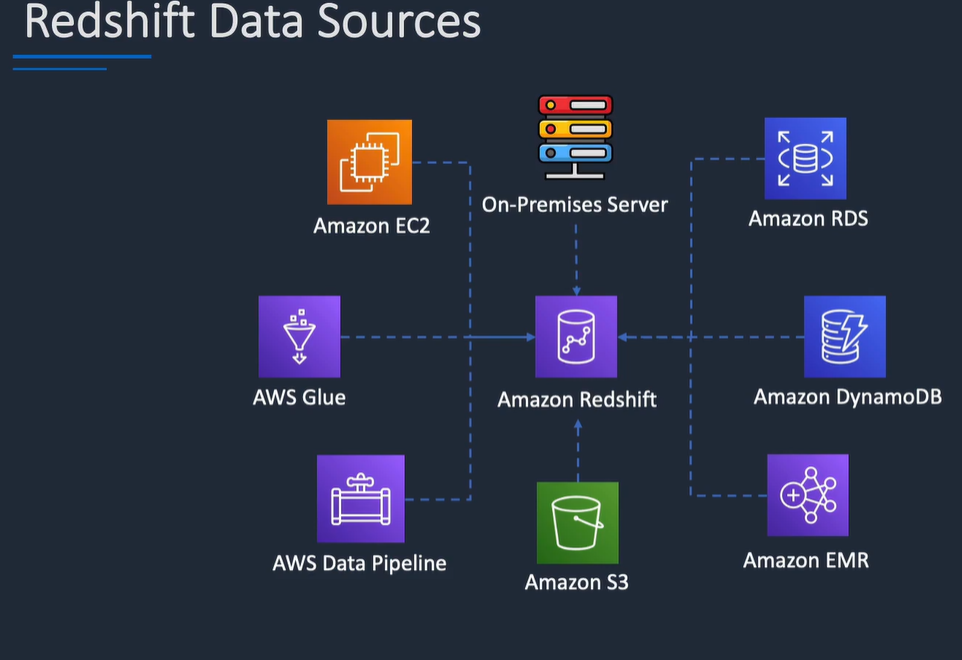
Amazon Redshift is a cloud-based data warehousing service from AWS that is designed to handle large-scale data analytics and queries efficiently. It enables organizations to perform complex analytical queries on massive datasets quickly and cost-effectively.