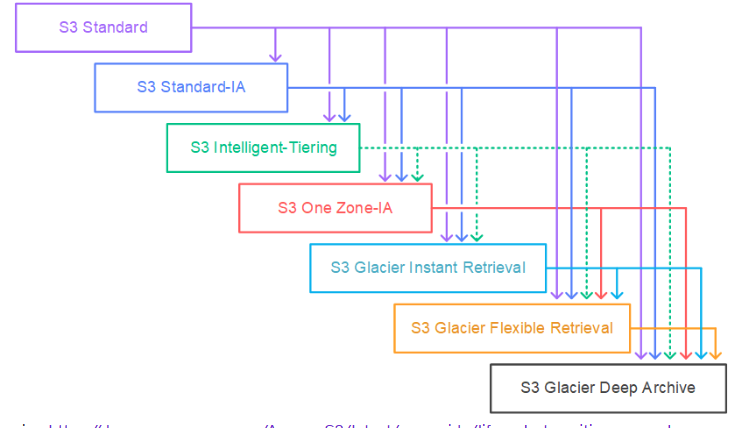
AWS S3 lifecycle policies allow you to automatically manage the lifecycle of your objects in S3 buckets. These policies help you transition objects between different storage classes or delete them after a certain period of time. This can help reduce costs by automatically moving less frequently accessed data to cheaper storage options or by deleting old, unneeded data.
Transition Actions: Move objects between storage classes.
- STANDARD → INTELLIGENT_TIERING: Automatically move to different storage tiers based on access patterns.
- STANDARD → GLACIER or DEEP_ARCHIVE: Move to cold storage for long-term archiving.
- INTELLIGENT_TIERING → GLACIER or DEEP_ARCHIVE: Transition objects that are infrequently accessed to even cheaper storage.
Expiration Actions: Automatically delete objects.
- Can be set to delete objects after a specific number of days or on a particular date.
- You can also set expiration policies for incomplete multipart uploads.
Noncurrent Version Expiration: Automatically delete old versions of objects.
If versioning is enabled, you can delete noncurrent (older) versions after a set period of time.
Resources